Response-Based and Counterfactual Learning for Sequence-to-Sequence Tasks in NLP: An Overview
I have written a blog post as a summary of my PhD thesis. In my thesis I explored how to learn from feedback given to model outputs when the collection of direct supervision signals is too costly. I also built a natural language interface to the geographical database OpenStreetMap.”
Teaser
“We all need people who will give us feedback. That’s how we improve.” - Bill Gates, TED Talks Education, May 2013
Motivation
We all know that supervised data is expensive to obtain. So let’s ask the following question: What if we learn from feedback given to model outputs instead?
Next to reducing the requirement for supervised data, learning from feedback also has several other advantages:
- Even if supervised data is given, we want to also discover alternative good outputs.
- With feedback given to model outputs, we can improve over time.
- It is possible to personalise a system to a specific use case or user.
For these reasons, I explored how to learn from feedback for sequence-to-sequence tasks in NLP in my PhD thesis.
The scenario I assume in my thesis can be summarized with the following picture:
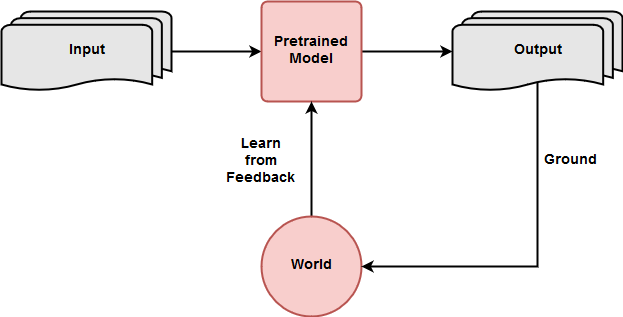
A pre-trained model receives an input for which it produces one or several outputs. An output is grounded in a given external world which assigns some feedback to it. The feedback is then used to update the pre-trained model.